(If you want to write up your answers using Markdown, here is a template you can use to get started.)
Reminders:
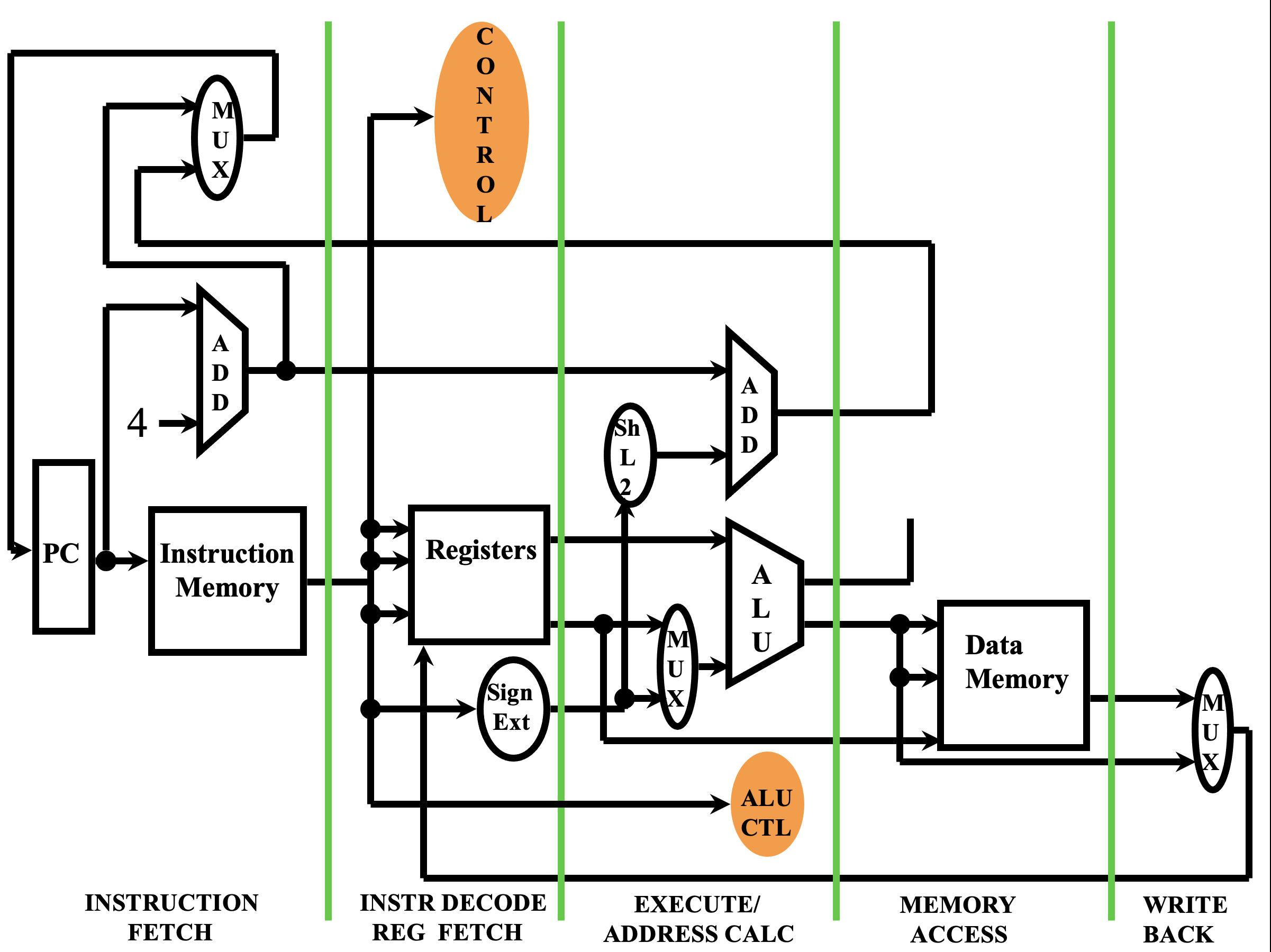
In a single-cycle datapath, one instruction is executed in each clock "tick". In other words, the clock cycle time is set to the time it takes any instruction to fully execute. Since each "tick" takes the same amount of time, each instruction must take the same amount of time.
In both a multi-cycle datapath and a pipelined datapath, a clock "tick" is how long the instruction spends in each stage of the datapath. With each "tick" the instruction moves to the next stage. Since each "tick" takes the same amount of time, each stage must take the same amount of time.
In a multi-cycle datapath, instructions are executed one at a time, but only go through the stages that they need to. (E.g., R-format instructions do not have to go through MEM, because they don't read or write to memory.) In a pipelined architecture, as each instruction moves to the next stage, the following instruction moves into the stage behind it.
This summary of single-cycle, multi-cycle, and pipelined datapaths might be helpful.
Each datapath stage has a latency time associated with it, which is the minumum amount of time required for the stage to do its job. Depending on the datapath type, though, an instruction might have to spend longer in a stage than its latency requires.
An example set of stages, with latencies, might be:
Based on the information above, complete the following table and the exercises that follow it.
| Question | Single-cycle datapath | Multi-cycle datapath | Pipelined datapath |
|---|---|---|---|
| Given the latencies described above, what would be the clock
cycle time?
|
|||
| Are all stages the same length?
|
|||
How long would an add instruction take?
|
|||
How long would a lw instruction take?
|
|||
How long would a sw instruction take?
|
|||
How long would a beq instruction take?
|
|||
Assuming there are no stalls or hazards, how long should it
take to execute a program with 1000 instructions if
the percentage of each type of instruction matches the distribution
below?
|